5.6. Concentration et exploitation des logs applicatifs¶
5.6.1. Besoins¶
Contrairement aux journaux applicatifs, les logs techniques générés par les applications ne participent pas à la valeur probante et à la preuve systèmique du SAE. Il n’y a donc pas de besoin métier sur la non perte de logs. Cependant, étant donné la présence notable des alertes de sécurité, un effort est fait pour réduire au maximum les risques de perte de logs.
5.6.2. Modèle générique¶
On peut noter les composants suivants :
- Emetteur du log : il s’agit de l’application qui est à l’origine du log
- Agent de transport du log : il s’agit d’un composant recevant tous les logs associés à un serveur/VM (mais pas container)
- Concentrateur du log : il s’agit de la cible de réception du log .
- Stockage des logs : il s’agit du composant stockant les logs (de manière plus ou moins requêtable)
- Visualisation des logs : il s’agit du composant (souvent IHM) qui permet la recherche et la visualisation des logs
Les échanges doivent se faire selon des protocoles données :
- Protocole d’emission du log (entre emetteur et agent de transport)
- Protocole de transport du log (entre agent de transport et concentrateur)
L’architecture générique peut être vue de la manière suivante :
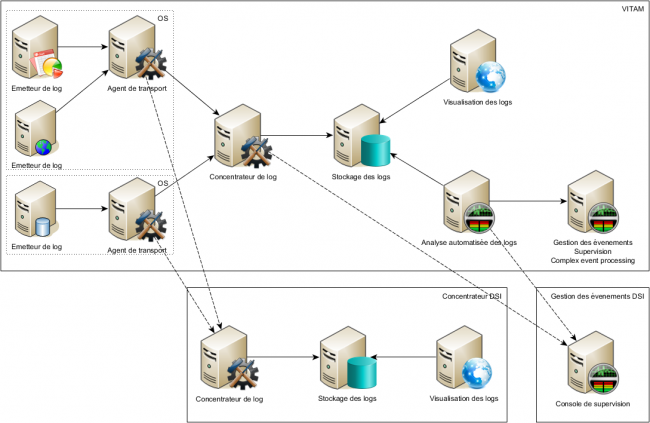
Architecture générique d’un système de gestion de logs.
VITAM n’implémente qu’une sous partie de cette architecture générique (la centralisation / stockage / visualisation), mais permet l’intégration d’un composant externe de gestion de logs.
5.6.3. Choix des implémentations¶
De manière générale, l’implémentation s’appuie fortement sur une architecture syslog.

Architecture du sous-système de centralisation des logs
Cette implémentation vise à éviter au maximum les pertes de logs ; cela implique notamment l’utilisation de buffers stockant temporairement les logs en cas de déconnexion réseau, et l’utilisation de protocole non reliables (ex: UDP) uniquement sur des liens réseaux locaux à une instance (ex: boucle locale).
5.6.3.1. Emetteur de logs¶
Dans le système VITAM, l’émetteur des logs peut être :
- Pour les composants logiciels Java VITAM : l’appender logback SyslogAppender ;
- Pour les script unix : la commande
logger.
Un émetteur de logs a les responsabilités suivantes :
- Le formattage du message selon le format de log préconisé pour l’application ;
- L’envoi des logs à l’agent de transport de logs selon le protocole défini dans la section présentant les principes de log.
5.6.3.2. Agent de transport de log¶
L’agent de transport de log est rsyslog. Il est installé localement sur chaque serveur hébergeant des composants logiciels du système VITAM.
Il a les responsabilités suivantes :
- L’acquisition des logs au format syslog UDP (sur le port par défaut 514) et syslog unix (
/dev/log) ; - Le buffering des logs (utilisation d’une action queue rsyslog de type « Disk-Assisted Memory Queue ») ;
- La transmission des logs au concentrateur.
Note
Rationale : il s’agit de l’agent syslog par défaut sur les distributions supportées par Vitam, et il présente une consommation mémoire limitée (notamment par rapport à d’autres solutions en Java ou Ruby).
Le protocole de transport du log (entre agent de transport et concentrateur) doit être conforme au format syslog tcp (RFC 3195, basé sur la RFC 3164).
Note
Ce format est est privilégié car il est un bon compromis entre fiabilité (sécurité d’acheminement de TCP) et exploitabilité . Il n’y a en effet pas de contraintes imposant des protocoles plus “reliable” comme RLTP ou RELP.
En se basant sur la RFC 5424, les paramètres imposés sur les messages syslog sont identiques aux paramètres décrits dans la section présentant les principes de log.
5.6.3.3. Concentration de logs¶
Le concentrateur de logs est logstash. Il est instancié de manière unique ou en cluster, et a les responsabilités suivantes :
- Acquisition des logs au format syslog TCP (RFC 3164) ;
- Parsing des logs pour en extraire la structure ;
- Dépôt des logs dans le stockage de logs.
5.6.3.4. Stockage des logs¶
Le stockage des logs se fait dans le moteur d’indexation ElasticSearch, dans un cluster dédié au stockage des logs (pour séparer les données de logs et les données métier d’archives).
La configuration de ce cluster dépend de la taille du déploiement VITAM envisagé. Des dimensionnements indicatifs sont disponibles dans une section dédiée. Le paramétrage par défaut des shards et replicas est le suivant :
- Nombre nominal de shards primaires par index : 4 ;
- Nombre nominal de replica : 1 ;
Note
Les abaques proposées correspondent à un compromis en terme d’usage des resources VS résilience du système. Ces paramètres peuvent être changés si un besoin plus fort de résilience était identifié. Dans ce cas, on peut augmenter le nombre de noeuds ainsi que le nombre de replica, en veillant à ce que le nombre de shards primaires ne soit jamais inférieur au nombre de noeuds du cluster, et que le nombre de replica ne soit jamais supérieur au nombre de noeuds du cluster - 1.
Prudence
Une modification du nombre de shards primaires d’un index est une opération coûteuse à réaliser sur un cluster en cours de fonctionnement et qui doit dans la mesure du possible être évitée (indisponibilité du cluster et/ou risque de corruption et de perte de données en cas de problème au cours de l’opération) ; le bon dimensionnement de cette valeur doit être réalisé dès l’installation du cluster.
Index : chaque index stockant des données de logs correspond à 1 jour de logs (déterminé à partir du timestamp du log). Les index définis sont les suivants :
logstash-vitam-YYYY.MM.ddpour les messages concernant les composants de la solution VITAM, avec un type de données par format de logs, i.e. :- type
logbackpour les logs issus des applications Java ; - type
scriptspour logs issus des scripts ; - type
mongopour les logs de mongodb ; - type
elasticpour les logs d’elasticsearch (cluster métier).
- type
logstash-logs-YYYY.MM.ddpour les logs issus du sous-système de logs, avec un type de données par format de logs, i.e. :- type
elasticpour les logs d’elasticsearch (cluster de logs) ; - type
logstashpour les logs de logstash (WARNou plus) ; - type
kibanapour les logs issus de Kibana. - type
curatorpour les logs issus de Curator.
- type
logstash-failure-YYYY.MM.dd(1 par jour ; le jour correspond au jour de l’horodatage des messages), pour les messages correspondant à un échec de parsing..kibanapour le stockage des paramètres (et notamment des dashboards) Kibana.
Prudence
Dans le cadre de cette version de la solution VITAM, cette réflexion n’intègre pas la problématique des traces associées aux actions utilisateur (par exemple : accès au système, lancement d’une opération sur les archives, consultations d’archives, échec d’authentification, refus d’accès, …) ; cette problématique est encore en cours d’étude, notamment pour en définir les besoins en terme de criticité (et notamment la non-perte d’information, leur degré de confidentialité et d’intégrité), et sera potentiellement prise en compte par un autre sous-système.
5.6.3.4.1. Gestion des index¶
La création des templates d’index et des index doit être réalisée par l’application à l’origine de l’écriture dans Elasticsearch (kibana pour l’index .kibana, logstash pour les autres index). La gestion des index est réalisée par l’application Curator. Le paramétrage est réalisable par l’exploitant (cf. DIN). Les valeurs suivantes sont recommandées :
- Durée de maintien des index « online » : 30 jours ; cela signifie qu’au bout de 30 jours, les index seront fermés, et n’apparaîtront donc plus dans l’IHM de suivi des logs. Cependant, ils sont conservés, et pourront donc être réouverts en cas de besoin.
- Durée de conservation des index : 365 jours ; au bout de cette durée, les index seront supprimés.
5.6.3.5. Visualisation des logs¶
La visalisation des logs se fait par le composant Kibana. Il est instancié de manière unique, et persiste sa configuration dans ElasticSearch (dans l’index .kibana).
Aucun mécanisme d’authentification n’est mis en place pour sécuriser l’accès à Kibana.
Indication
La version opensource de Kibana, utilisée dans VITAM, ne supporte pas nativement l’authentification des clients ; d’autres solutions peuvent être mises en place (ex: l’utilisation du composant Security), sous réserve d’une étude de compatibilité de la solution choisie.
5.6.4. Intégration à un système de gestion de logs existants¶
L’intégration à un autre système de logs (pour y dupliquer les logs) est possible ; deux points d’ancrage sont possibles :
- au niveau de logback ; ce point d’extension ne permet que d’obtenir les logs en provenance des applicatifs métier (java) ; ce point d’extension est par conséquent déconseillé ;
- au niveau de rsyslog ; ce point d’extension permet d’agir sur les logs provenant de tous les composants déployés (y compris les bases de données et d’autres composants d’infrastructure déployés dans le cadre de VITAM). C’est le point d’extension conseillé en cas d’intégration avec un système de gestion de logs externe.
Astuce
Les règles de grok fournies avec le composant logstash (disponibles dans le répertoire de configuration de composant) sont un bon point de départ pour intégrer le format des différents logs dans un système de gestion de logs tiers.
5.6.5. Limites¶
La solution implémentée dans Vitam possède les limites connues suivantes :
- Cette solution réutilise les principes de centralisation de logs basés sur les systèmes syslog ; par conséquent, elle en hérite certaines de leurs limites, et notamment l’absence de sécurité dans les protocoles syslog (udp ou tcp) (absence d’authentification, de vérification d’intégrité ou de confidentialité des informations).
- Aucune brique d’alerting n’est intégrée dans cette version de la solution logicielle VITAM.
Astuce
Il est à noter que les logs ne sont pas complètement perdus en cas de perte du système de centralisation des logs ; en effet, ils sont dans tous les cas déposés dans des fichiers locaux aux noeuds.